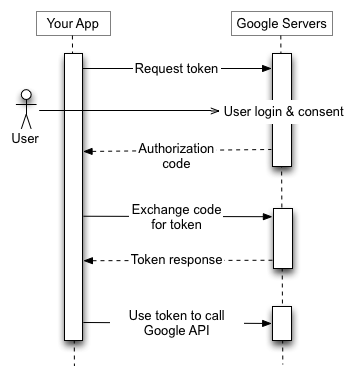
Process Flow of Authentication and Authorization using OAuth 2.0 Protocol :
Fig: Process flow of Authentication through Google using OAuth 2.0
The whole process flow described above involves four steps. Firstly, the OAuth 2.0 credentials like client ID and client secret are obtained from the provide(Google Developers Console in this case) for the web application. Now, to access any API, one needs to get the access token from the provider using the set of client ID and client Secret . After the user login, the user is asked whether they are willing to grant the permissions that the application is requesting. This process is called user consent. If the user grants the permission, the provider Authorization Server sends the application an access token (or an authorization code that the application can use to obtain an access token). After the application obtains an access token, it sends the token to the Provider API in an HTTP authorization header. Access tokens have limited lifetimes. If the application needs access to provider's API beyond the lifetime of a single access token, it can obtain a refresh token. A refresh token allows an application to obtain new access tokens.
This is the whole workflow of the authorization using OAuth 2.0 protocol.
Majorly three django packages are used for integrating social authentication. Below, they are described briefly:
Django-allauth:
It is an integrated set of Django applications addressing authentication, registration, account management as well as 3rd party (social) account authentication. In simple terms, it is a combination of simple login and registration along with social authentication system.
Django-Allauth is the most popular Django package used for Authentication purposes. Best thing about it is that it is available as open source which speeds up the development process due to collaborations with the developers all around the world.
Advantages of Django-allauth:
Support for Python 2.6, 2.7 and 3.3
Support for Django Version 1.4.3 and above.
Supports Social authentication through Dropbox and google using OAuth2.0
Supports multiple authentication schemes (e.g. login by user name, or by e-mail)
Multiple strategies for account verification (ranging from none to e-mail verification)
Support to connect multiple social accounts to a Django user account.
Consumer keys, tokens make use of the Django sites framework. This is especially helpful for larger multi-domain projects, but also allows for for easy switching between a development (localhost) and production setup without interfering with your settings and database.
Rapidly gaining traction and improving day by day.
FAQ page solves most of the problems related to Django-allauth. Otherwise most problems are solved on StackOverflow under the tag #django-allauth. Also mailing list is also available to solve further issues if any.
It is well tested than other Django authentication packages; credits to consistent development work going on.
The installation, configuration is easy to get started with.
Pre-defined templates are available. Its upto the developer whether he wants to customize them or not.
Also, one can easily add the new backends if required.
Disadvantages of django-allauth:
While working on it and researching more about it, I found that it has some documentation gaps that need to be fixed.
It can get problematic for beginners since it involves series of small but time-consuming hurdles.
Django Social Auth:
Django Social-auth library is a Django package that was made for the social authentication. But the library is deprecated now and has migrated to Python-social-auth for providing better support to several frameworks and ORMs.
Advantages of Django-Social-Auth:
Provides social authentication using OAuth and OpenId mechanism
Support for Django, Flask, Pyramid, Webpy frameworks.
Disadvantages of Django-Social-auth:
This package is deprecated.
No support for Python 3.x
Development on its codebase has stopped.
Not well documented. It lacks FAQ page for bug fixing.
Python-Social-Auth:
Python social-auth is easy-to-setup authentication system that provides vast support. It supports several frameworks and auth providers. It has migrated from django-social-auth to generalize the package to provide a vast support and implement a common interface to define new authentication providers from third-parties and bring support for more frameworks and ORMs.
Advantages of Python-Social-auth:
Provides support for frameworks such as Django, Flask, Webpy, Pyramid and Tornado.
Supports Python 3.x
Supports social authentication through Dropbox, Google, etc. using OAuth 2.0
Frameworks API is provided that ease the implementation to increase the number of frameworks supported.
-
Storage API is provided to add support to more ORMs.
Multiple social accounts can be associated to a single user.
Basic user data population, to allow custom fields values from providers response.
Disadvantages of Python Social-Auth:
Not well documented.
Newer package. So, we cannot predict the future developments.
Lot of issues(98 issues) are listed on Github.
Comparison between the three authentication packages:
Features
|
Django-Allauth
|
Django-Social-auth
|
Python-Social-auth
|
Commits on Codebase
|
Regular and fast- developing
|
No commits made since 6 months.
|
Regular commits on codebase
|
Python 3.x Support
|
YES
|
NO
|
YES
|
Authentication
|
Simple authentication +
Social authentication
|
Only
Social authentication
|
Only
Social authentication
|
Predefined and customizable
Templates
|
YES
|
NO
|
NO
|
Framework Support
|
Django
|
Django, Flask, Webpy, Pyramid and Tornado
|
Django, Flask, Webpy, Pyramid and Tornado
|
Total Commits
|
1072
|
1611
|
1384
|
Development Status
|
Beta
|
Beta
|
Beta
|
OAuth 2.0 Support
|
YES
|
YES
|
YES
|
Current Stable Version
|
0.19.1
|
0.7.28
|
0.2.2
|
Support for Dropbox and Google
|
YES
|
YES
|
YES
|
Repository Forks
|
545
|
735
|
458
|
Total no. of Contributors
|
150
|
167
|
148
|
Repo. watchers
|
1650
|
2169
|
1502
|
Selecting the Appropriate Package:
The package which does not affects the scalability of the project must be given more weightage among all other packages.
From previous work experience and research on authentication libraries, Django-Allauth turns out to be the most appropriate choice of them all. So. in my view, django-allauth should be used for integration.